Here one can find the derivation of the set of Equations (12) in Section 4.2 of Ontwikkeling van gebiedsdekkende kaartlagen van gemodelleerde bodemeigenschappen op basis van het bodemkoolstofmonitoringnetwerk Cmon.[1] These equations are used to estimate the mean and variance of soil descriptors within spatial units — hereafter referred to as soil units — based on Digital Soil Maps (DSM). The derivation was omitted from the aforementioned report due to its length and technicality. Nevertheless, it is an important extension on the DSM methodology and is presented here in a concise form for reference.
The DSM model
A DSM model describes the distribution of measurements at a given location l as:
Y_l=μ_l+ε_l
where Y_l denotes the distribution of soil descriptor measurements y_l at location l, \mu_l the shorthand notation for the deterministic component \mu(\lambda_l) of the model where \lambda_l≔\{s_l,c_l,o_l,r_l,p_l,a_l,n_l\} the set of covariates characterizing that location l, and finally \varepsilon_l the shorthand notation for the aleatoric (i.e., residual) variance function \varepsilon(\lambda_l) capturing the measurement error and any unexplainable local variability. The model is assumed to be non-linear and satisfying \mathbb{E}[\varepsilon_l]=0 and \mathrm{Var}[\varepsilon_l]=\sigma_l^2. No distributional requirement on Y_l is imposed.
Mixture distribution
A soil unit U is defined as a finite set of |U| spatial locations l. If one would measure a soil descriptor at every possible soil unit location, these measurements would form distribution Y, which is a finite mixture of location-specific distributions Y_l.
The quantities of interest are the expectation \mu = \mathbb{E}[Y] and variance \sigma^2 = \mathrm{Var}[Y] of the mixture distribution Y. The remainder of this article derives solutions for \mu and \sigma^2 in terms of the location-specific means \mu_l and variances \sigma^2_l (i.e., the DSM products).
Naive estimates
Since |U| is finite, the expectation follows directly as the average of all possible locations:
\mu =\mathbb{E}\left[Y\right] =\frac{1}{|U|}\sum_{l\in U}\mathbb{E}[Y_l] =\frac{1}{|U|}\sum_{l\in U}\mu_l \tag{a}The variance follows from the law of total variance:
\begin{align*} \sigma^2 &=\mathrm{Var}\left[Y\right] =\mathbb{E}_U\left[\mathrm{Var}\left[Y_l\right]\right]+{\mathrm{Var}}_U\left[\mathbb{E}\left[Y_l\right]\right]\\ &=\underbrace{\frac{1}{|U|}\sum_{l\in U}\sigma_l^2}_{\sigma_{within}^2} + \underbrace{\frac{1}{|U|}\sum_{l\in U}\left(\mu_l-\mu\right)^2}_{\sigma_{between}^2} \tag{b}\end{align*}These are exact solutions for \mu and \sigma^2 provided the DSM products represent the true \mu_l and \sigma^2_l. In practice only their estimates \hat{\mu}_l and \hat{\sigma}^2_l are available. How to obtain those estimates is explained in Section 2.1.1 and 2.1.4 of the aforementioned report[1]. The naive (plug-in) estimates \hat{\mu} and \hat{\sigma}^2 are obtained by replacing the unknown true quantities \mu_l and \sigma^2_l in (a) and (b) with their DSM-estimates \hat{\mu}_l and \hat{\sigma}^2_l.
Unbiased estimates
For non-linear machine-learning models such as Random Forests, finite-sample unbiasedness is generally not guaranteed. Plugging \hat{\mu}_l into equation (a) and taking the expectation makes the bias term b apparent:
\mathbb{E}\left[\hat{\mu}\right]=\mathbb{E}\left[\frac{1}{|U|}\sum_{l\in U}{\hat{\mu}}_l\right]=\frac{1}{|U|}\sum_{l\in U}\mathbb{E}\left[{\hat{\mu}}_l\right]=\frac{1}{|U|}\sum_{l\in U}\left(\mu_l+b_l\right)=\mu+bwhere b_l=\mathbb{E}\left[{\hat{\mu}}_l\right]-\mu_l is the predictive bias term. In practice, careful model selection and validation aim to make this bias negligible. It is therefore commonly assumed that b_l fluctuates around zero without systematic trend, implying b\approx0. The plug-in estimator \hat{\mu} is therefore approximately unbiased under this assumption.
For the variance, the situation is more involved. Here it is assumed that \hat{\sigma}^2_l is estimating MSPE:
\begin{align*} \hat{\sigma}_l^2 &=\mathbb{E}\left[{\hat{\varepsilon}}_l^2\right]\\ &=\mathbb{E}\left[\left(Y_l-{\hat{\mu}}_l\right)^2\right]\\ &=\mathbb{E}\left[\left(\varepsilon_l+(\mu_l-{\hat{\mu}}_l)\right)^2\right]\\ &=\mathbb{E}\left[\varepsilon_l^2\right]+\mathbb{E}\left[\left(\mu_l-{\hat{\mu}}_l\right)^2\right]+2\mathbb{E}\left[\varepsilon_l\left(\mu_l-{\hat{\mu}}_l\right)\right]\\ &=\mathbb{E}\left[\varepsilon_l^2\right]+\left(\mathbb{E}\left[{\hat{\mu}}_l\right]-\mu_l\right)^2+\mathbb{E}\left[\left({\hat{\mu}}_l-\mathbb{E}\left[{\hat{\mu}}_l\right]\right)^2\right]+2\mathbb{E}\left[\varepsilon_l\left(\mu_l-{\hat{\mu}}_l\right)\right]\\ &=\sigma_l^2 + \underbrace{\mathrm{Bias}^2\left[\hat{\mu}_l\right]}_{b_l^2} +\underbrace{\mathrm{Var}\left[\hat{\mu}_l\right]}_{v_l} +\underbrace{2\mathbb{E}\left[\varepsilon_l\left(\mu_l-\hat{\mu}_l\right)\right]}_{0\ \Leftrightarrow\ \varepsilon_l\ \bot\ \hat{\mu}_l} +\beta_l \end{align*}where \beta_l captures any additional systematic bias arising because the MSPE itself is estimated rather than known exactly. The term \mathbb{E}\left[\varepsilon_l\left(\mu_l-\hat{\mu}_l\right)\right] is assumed to vanish or at least be negligible when using leave-one-out or out-of-bag predictions \hat{\mu}_l in practice.
Now plugging \hat{\sigma}_l^2 into equation (b) and taking the expectation makes the bias terms apparent:
\begin{alignat*}{2} \mathbb{E}\left[{\hat{\sigma}}^2\right] &=&~&\frac{1}{|U|}\sum_{l\in U}\mathbb{E}\left[{\hat{\sigma}}_l^2\right]+\frac{1}{|U|}\sum_{l\in U}\mathbb{E}\left[\left({\hat{\mu}}_l-\hat{\mu}\right)^2\right]\\ &=&~&\frac{1}{|U|}\sum_{l\in U}\mathbb{E}\left[\sigma_l^2+b_l^2+v_l+\beta_l\right]\\ &&~&+\frac{1}{|U|}\sum_{l\in U}\mathbb{E}\left[\left(\left(\mu_l-\mu\right)+\left({\hat{\mu}}_l-\mu_l\right)-\left(\hat{\mu}-\mu\right)\right)^2\right]\\ &=&~&\sum_{l\in U}\frac{\sigma_l^2}{|U|}+\sum_{l\in U}\frac{v_l+b_l^2}{|U|}+\sum_{l\in U}\frac{\beta_l}{|U|} +\sum_{l\in U}\frac{\left(\mu_l-\mu\right)^2}{|U|}+\sum_{l\in U}\frac{v_l+b_l^2}{|U|}\\ &&~&-\sum_{l,k\in U}\frac{\mathrm{Cov}\left[{\hat{\mu}}_l,{\hat{\mu}}_k\right]}{|U|^2} -\left(\sum_{l\in U}\frac{b_l}{|U|}\right)^2\\ &=&~&\sigma^2+2\sum_{l\in U}\frac{v_l+b_l^2}{|U|}+\beta-\mathrm{Var} \left[\hat{\mu}\right]-b^2 \end{alignat*}Thus the plug-in estimator \hat{\sigma}^2 overestimates on average the true variance by approximately twice the average prediction variance, partially offset by the variance of the aggregated mean estimator.
Furthermore, two important observations follow from this derivation. First observation is that the term \sum_{l\in U}\frac{v_l+b_l^2}{|U|} arises twice: once for the bias in \hat{\sigma}_l^2, and once from the aggregation of the estimated means through the between-locations variability term. Consequently, even if \hat{\sigma}_l^2 was an unbiased estimator of \sigma_l^2, the soil unit level variance estimator \hat{\sigma}^2 would still be biased upward due to the estimation uncertainty in \hat{\mu}_l.
Second observation is that if \hat{\mu}_l are independent, the negative term \frac{\sum_{l,k\in U}\mathrm{Cov}\left[{\hat{\mu}}_l,{\hat{\mu}}_k\right]}{|U|^2} simplifies to \frac{\sum_{l\in U}Var\left[{\hat{\mu}}_l\right]}{|U|^2} which decays at rate \mathcal{O}(1/|U|^2). Under this assumption of independence and the assumption that the bias terms b_l and \beta_l are zero or negligible, the net bias in {\hat{\sigma}}^2 is strictly positive and requires correction. This leads to the following bias-corrected variance estimator:
S^2={\hat{\sigma}}^2-\left(2-\frac{1}{|U|}\right)\frac{1}{|U|}\sum_{l\in U}\mathrm{Var}\left[{\hat{\mu}}_l\right]This bias-corrected estimator S^2 is used in Equation (12) of the DSM report[1].
The bitter truth
The preceding derivations not only show the complexity of DSM-based estimation of \sigma^2, but also that multiple assumptions need to be met for it to be a reliable (i.e. unbiased) estimate. Conversely, a design-based estimator of \sigma^2 is unbiased as long as samples are taken randomly from soil unit locations. This then begs the question whether the extra complexity and assumptions of DSM-based estimators make up against the simplicity and reliability of design-based estimators.
")
 is the geometric center of the production process,
is the geometric center of the production process,  the trueness factor (or multiplicative systematic error) of the procedure, and
the trueness factor (or multiplicative systematic error) of the procedure, and  ,
,  and
and  the unit-centered lognormal random variables of respectively the production process variability (
the unit-centered lognormal random variables of respectively the production process variability ( ), and the between and within run variability of the procedure (
), and the between and within run variability of the procedure ( ). Note that production process parameters (i.e.
). Note that production process parameters (i.e.  and
and  are determined during validation at different levels of the true value and thus are a function of it.
are determined during validation at different levels of the true value and thus are a function of it. \ge 1 - \omega")
 . To make it more concrete, we can translate this into a comprehensible analytical target profile (ATP) which I base here on the latest (
. To make it more concrete, we can translate this into a comprehensible analytical target profile (ATP) which I base here on the latest ( = 1.049 RP, the expected probability of measured values (i.e. 1 run, 1 replicate) falling outside [0.70; 1.43] RP product specification limits is less than 1%.
= 1.049 RP, the expected probability of measured values (i.e. 1 run, 1 replicate) falling outside [0.70; 1.43] RP product specification limits is less than 1%.  and
and  and their dependence on the true value which is a random variable. (The suggested solutions in USP 1033 are ones-of-many and because of that may result in falsely rejecting a perfectly fine procedure.) More complex criteria are required. In the graph that follows the validation of the procedure is represented as a good compromise between complexity and intelligibility.
and their dependence on the true value which is a random variable. (The suggested solutions in USP 1033 are ones-of-many and because of that may result in falsely rejecting a perfectly fine procedure.) More complex criteria are required. In the graph that follows the validation of the procedure is represented as a good compromise between complexity and intelligibility.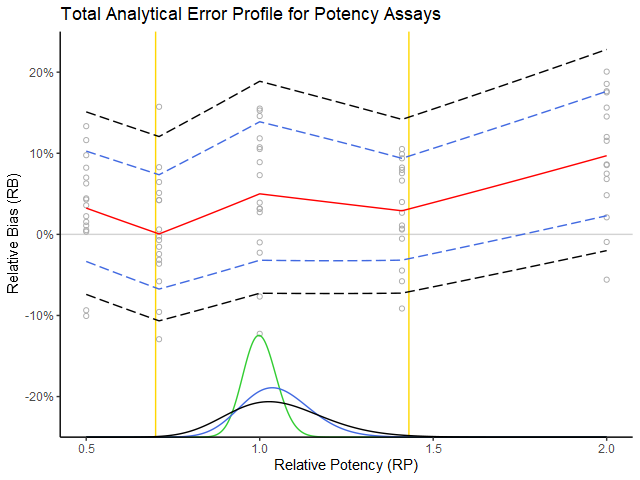

 and material signatures
and material signatures  called endmembers.
called endmembers.
 which measures the error between the actual pixels and the predicted pixels
which measures the error between the actual pixels and the predicted pixels  together with a regularization term
together with a regularization term ") that measures the size of the simplex formed by the endmembers.
that measures the size of the simplex formed by the endmembers. = ||\mathbf{X} - \mathbf{W}\mathbf{E}^T ||_F^2 + V(\mathbf{E})")
")
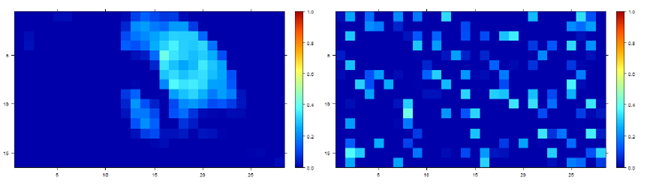
 = \sum_n \sum_m \text{Var}(\mathbf{u}_{n,m})")
 signifies the vector of the abundance and the adjacent abundances of the
signifies the vector of the abundance and the adjacent abundances of the  -th pixel and
-th pixel and  -th endmember. The new simplified objective functions becomes
-th endmember. The new simplified objective functions becomes = ||\mathbf{X} - \mathbf{W}\mathbf{E}^T ||_F^2 + V(\mathbf{E}) + S(\mathbf{W})")
")
 tend to be more smooth.
tend to be more smooth.